Natural Language Generation
In this article, we will focus on a particular branch of NLP called Natural Language Generation, or NLG.
We will implement an NLG model based on the dataset of the E2E competition. The goal is to output sentences describing the Meaning Representations given as input. Details about the E2E dataset can be found on the SIGDIAL 2017 paper.
The model will use the Keras library. Considering the time of training for such Neural Networks usecases, we will also use an instance on AWS EC2.
The setup
Nowadays, it is quite straightforward to have access to a powerful GPU in the cloud when a laptop CPU is not enough.
You can find more information on that nice article on Medium, but here is a summary version on how to get a Jupyter notebook with Keras in GPU mode on AWS:
- Connect to your AWS console and create a new instance
- Select the Deep Learning AMI (Ubuntu) and a p2.xlarge instance type
- Set up security group to configure port 8888 (for Jupyter notebook)
- Create a new key or use your existing one
- You can now connect from your machine via ssh running in a terminal:
ssh -i path/to/key ubuntu@your.instance.dns. - Launch jupyter notebook from your instance running
jupyter notebook --ip=0.0.0.0 --no-browser - Access jupyter from your local machine browser at
your.instance.ip:8888
And then the notebook can be ran just like usual !
AWS instance GPU sanity check
First of all, we want to make sure that the GPU of our AWS DLAMI is well detected by Tensorflow. If so, Keras will automatically use the cores of the GPU during the learning phase. Compared to running on a laptop CPU, we expect an overall training time reduced by at least a factor of 10.
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
(fname, cnt))
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 11589226778285653049
, name: "/device:XLA_GPU:0"
device_type: "XLA_GPU"
memory_limit: 17179869184
locality {
}
incarnation: 7355181882075574100
physical_device_desc: "device: XLA_GPU device"
, name: "/device:XLA_CPU:0"
device_type: "XLA_CPU"
memory_limit: 17179869184
locality {
}
incarnation: 11458837433106700691
physical_device_desc: "device: XLA_CPU device"
, name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 11286970368
locality {
bus_id: 1
links {
}
}
incarnation: 13819392677496865500
physical_device_desc: "device: 0, name: Tesla K80, pci bus id: 0000:00:1e.0, compute capability: 3.7"
]
Everything seems fine, the GPU is recognized by Tenforflow. We can see that we use an NVidia Tesla K80, which contains around 2500 CUDA cores.
Get what we need
Time to start! We have to load the data from the provided E2E files, and to do some pre-processing.
from __future__ import print_function
from keras.preprocessing.text import text_to_word_sequence
import numpy as np
import csv
import re
data_path = 'e2e-dataset/trainset.csv' # Path to the data
Using TensorFlow backend.
The dataset set only contains features columns, MR which stands for Meaning Representation, and ref which is the natural language sentence associated to the tags.
To undestand better why the dataset is structured like this, let’s take a look at an example of expected model behavior furnished on the E2E website:

The input we have to give to the encoder is MRs. However we cannot feed it like that, so we need some preprocessing:
We introduce start and stop tokens for each individual MR, and join all of them is a single string. We also try to keep the same order for the MRs, meaning if a token is not present for a given input, we replace it by start NULL stop to keep the order. This method is inspired by the paper by HarvardNLP.
The dataset contains 8 distinct MRS:
- name
- eatType
- food
- priceRange
- customerRating
- area
- kidsFriendly
- near
And we need to get for each row all of values for each MR, to then encapsulate it with start and stop tokens.
We use the same approach for the final output sentences, creating a beginning token with \t and an ending token with \n.
input_texts = []
target_texts = []
input_vocab = set()
target_vocab = set()
with open(data_path, 'r', encoding='utf-8') as f:
reader = csv.reader(f)
training_set = list(reader)
for element in training_set[1:]:
input_text = element[0]
name_text = re.search('(?<=name\[).+?(?=\])', input_text)
eatType_text = re.search('(?<=eatType\[).+?(?=\])', input_text)
food_text = re.search('(?<=food\[).+?(?=\])', input_text)
priceRange_text = re.search('(?<=priceRange\[).+?(?=\])', input_text)
customerRating_text = re.search('(?<=customer rating\[).+?(?=\])', input_text)
area_text = re.search('(?<=area\[).+?(?=\])', input_text)
kidsFriendly_text = re.search('(?<=familyFriendly\[).+?(?=\])', input_text)
near_text = re.search('(?<=near\[).+?(?=\])', input_text)
name_string = 'start_name ' + name_text.group(0) + ' stop_name' if name_text else 'start_name stop_name'
eatType_string = 'start_eatType ' + eatType_text.group(0) + ' stop_eatType' if eatType_text else 'start_eatType stop_eatType'
food_string = 'start_food ' + food_text.group(0) + ' stop_food' if food_text else 'start_food stop_food'
priceRange_string = 'start_priceRange ' + priceRange_text.group(0) + ' stop_priceRange' if priceRange_text else 'start_priceRange stop_priceRange'
customerRating_string = 'start_customerRating ' + customerRating_text.group(0) + ' stop_customerRating' if customerRating_text else 'start_customerRating stop_customerRating'
area_string = 'start_area ' + area_text.group(0) + ' stop_area' if area_text else 'start_area stop_area'
kidsFriendly_string = 'start_kidsFriendly ' + kidsFriendly_text.group(0) + ' stop_kidsFriendly' if kidsFriendly_text else 'start_kidsFriendly stop_kidsFriendly'
near_string = 'start_near ' + near_text.group(0) + ' stop_near' if near_text else 'start_near stop_near'
input_string = ' '.join([name_string, eatType_string, food_string, priceRange_string, customerRating_string, area_string, kidsFriendly_string, near_string])
input_texts.append(input_string)
target_text = element[1]
target_text = '\t ' + target_text + ' \n'
target_texts.append(target_text)
input_vocab = set(text_to_word_sequence(" ".join(input_texts), filters='!"#$%&()*+,-./:;<=>?@[\]^`{|}~'))
target_vocab = set(text_to_word_sequence(" ".join(target_texts), filters='!"#$%&()*+,-./:;<=>?@[\]^`{|}~'))
input_text_modif = []
for input_text in input_texts:
input_text_modif.append(' '.join(text_to_word_sequence(input_text, filters='!"#$%&()*+,-./:;<=>?@[\]^`{|}~', lower=True)))
target_text_modif = []
for target_text in target_texts:
target_text_modif.append(' '.join(text_to_word_sequence(target_text, filters='!"#$%&()*+,-./:;<=>?@[\]^`{|}~', lower=True)))
input_texts = input_text_modif
target_texts = target_text_modif
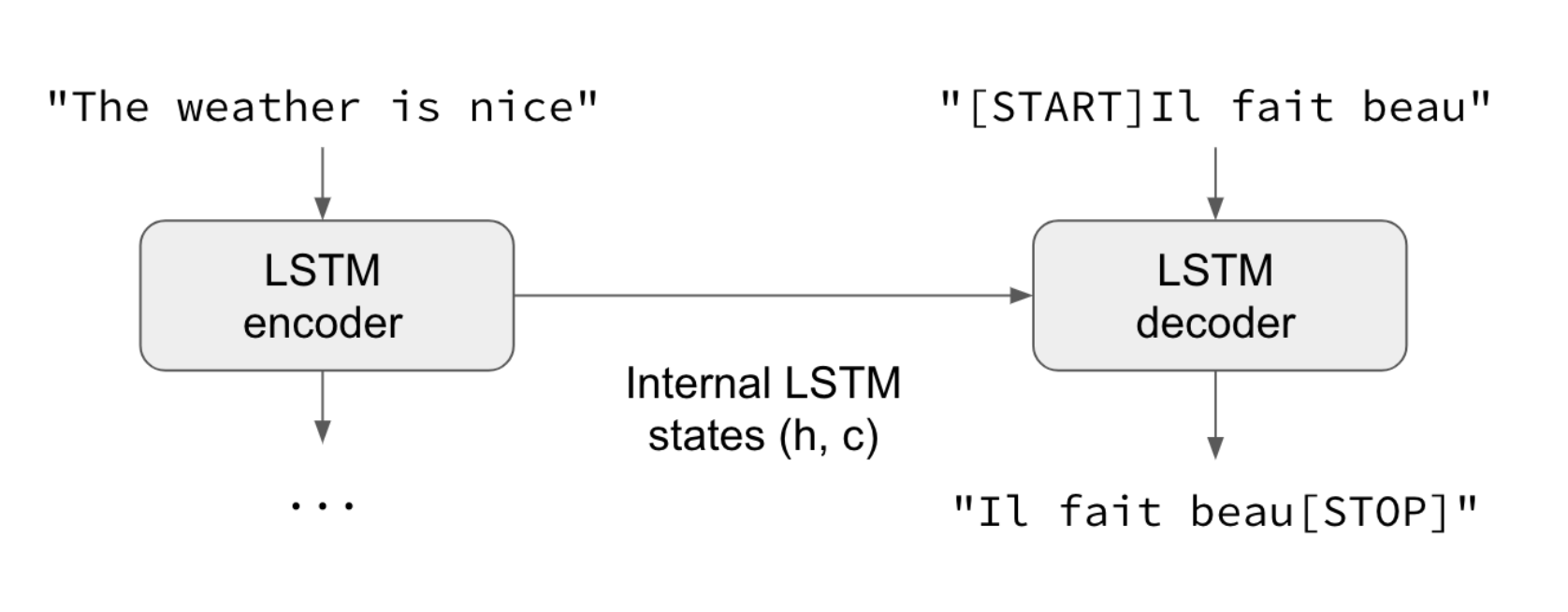
Originally created for text translation, a model now widely used for NLG in general is an Encoder-Decoder system.
In summary, the Encoder Neural Network is processing the input sequences, and transmitting its state to the decoder. The state is used as the “context” by the decoder, and the actual output of the Encoder is discarded.
Then the Decoder Neural Network is trained to predict the next token of the target sequence, given previous tokens of the target sequence and the input context.
For that reason, we need to create 3 dimensionnal arrays:
- The
encoder_input_data: A representation of the MR string. Each string is represented by a matrix MN (M = max number of words because we use padding, N = size of vocabulary) of one hot encoded tokens. - The
decoder_input_dataanddecoder_output_data: Same representation than encoder_input_data, but for the target sentences. The input and output are representations of the same sequence but offset by one timestep.
input_vocab = sorted(list(input_vocab))
target_vocab = sorted(list(target_vocab))
num_encoder_tokens = len(input_vocab)
num_decoder_tokens = len(target_vocab)
max_encoder_seq_length = max([len(txt.split(" ")) for txt in input_texts])
max_decoder_seq_length = max([len(txt.split(" ")) for txt in target_texts])
print('Number of samples:', len(input_texts))
print('Number of unique input tokens:', num_encoder_tokens)
print('Number of unique output tokens:', num_decoder_tokens)
print('Max sequence length for inputs:', max_encoder_seq_length)
print('Max sequence length for outputs:', max_decoder_seq_length)
Number of samples: 42061
Number of unique input tokens: 128
Number of unique output tokens: 2566
Max sequence length for inputs: 34
Max sequence length for outputs: 70
We will now create two dictionaries: one with the words of the input and the other with the words of the target
input_token_index = dict(
[(wor, i) for i, wor in enumerate(input_vocab)])
target_token_index = dict(
[(wor, i) for i, wor in enumerate(target_vocab)])
We generate the 3 dimensional vectors described above, with:
- The first dimension as the number of samples we have in the input.
- The second dimension as the maximum sequence length (for encoder or decoder).
- The third dimension as the number of unique input/target tokens we have.
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, wor in enumerate(input_text.split(" ")):
encoder_input_data[i, t, input_token_index[wor]] = 1.
for t, wor in enumerate(target_text.split(" ")):
decoder_input_data[i, t, target_token_index[wor]] = 1.
if t > 0:
decoder_target_data[i, t - 1, target_token_index[wor]] = 1.
Building the model(s) and learn
We have everything we want to train! The data is loaded and properly tranformed. We now define the Encoder and Decoder models. As a reminder, here is an example provided by Keras of the model architecture, here used for translation:
# Needed components from Keras
from keras.models import Model
from keras.layers import Input, LSTM, Dense
# Parameters definition
batch_size = 64 # Batch size for training.
epochs = 100 # Number of epochs to train for.
latent_dim = 256 # Latent dimensionality of the encoding space.
# Build encoder
encoder_inputs = Input(shape=(None, num_encoder_tokens)) # unique input tokens
encoder = LSTM(latent_dim, return_state=True) # number of neurons
encoder_outputs, state_h, state_c = encoder(encoder_inputs)
encoder_states = [state_h, state_c] # We discard the outputs
# Build the decoder, using the context of the encoder
decoder_inputs = Input(shape=(None, num_decoder_tokens)) # unique output tokens
decoder_lstm = LSTM(latent_dim, return_sequences=True, return_state=True) # internal states for inference on new data
decoder_outputs, _, _ = decoder_lstm(decoder_inputs,
initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
The model used for training is built! We use for each of the Neural Networks Long Short Term Memory layers, as they are very good in text processing usecases to be “context aware”.
Time for training. We use the rmsprop optimizer, and the categorical_crossentropy loss function given that the problem is technically a multi-class classification problem (we predict among a given amount of token).
Even on the AWS MLAMI instance with a K80 GPU, training on 100 epochs will take a while.
# Run training
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
model.fit([encoder_input_data, decoder_input_data], decoder_target_data,
batch_size=batch_size,
epochs=epochs,
validation_split=0.2)
Train on 33648 samples, validate on 8413 samples
Epoch 1/100
33648/33648 [==============================] - 213s 6ms/step - loss: 1.0962 - val_loss: 0.7423
Epoch 2/100
33648/33648 [==============================] - 202s 6ms/step - loss: 0.6523 - val_loss: 0.5895
...
Epoch 99/100
33648/33648 [==============================] - 203s 6ms/step - loss: 0.1573 - val_loss: 0.5616
Epoch 100/100
33648/33648 [==============================] - 203s 6ms/step - loss: 0.1569 - val_loss: 0.5636
<keras.callbacks.History at 0x7fcf9d3b75f8>
Finally, after approximately 6 hours of learning our model is ready. We can save it as a file to use later without running again this cell.
model.save('s2s.h5')
Make the machine talk
The following part is a bit different from conventionnal machine learning problems. The process of prediction here requires to create a new Encoder-Decoder model to do inferences.
During prediction, the inference_encoder model is used to encode the input sequence once which returns states that are used to initialize the inference_decoder model. From that point, the inference_decoder model is used to generate predictions step by step.
After that, we turn back the predictions of the decoder to tokens from our dictionary.
Let’s first define the model(s):
encoder_model = Model(encoder_inputs, encoder_states)
decoder_state_input_h = Input(shape=(latent_dim,))
decoder_state_input_c = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_model = Model(
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
And then the dictionnary to translate back to tokens:
reverse_input_token_index = dict(
(i, wor) for wor, i in input_token_index.items())
reverse_target_token_index = dict(
(i, wor) for wor, i in target_token_index.items())
We define a function for the prediction to make the process easier:
# Function making the predictions with the new Encoder-Decoder model
def decode_sequence(input_seq):
states_value = encoder_model.predict(input_seq) # Encode the input
target_seq = np.zeros((1, 1, num_decoder_tokens)) # Empty target sequence of length 1
target_seq[0, 0, target_token_index['\t']] = 1. # Start token for target
stop_condition = False
decoded_sentence = ''
while not stop_condition:
output_tokens, h, c = decoder_model.predict(
[target_seq] + states_value)
# Sample a token
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_wor = reverse_target_token_index[sampled_token_index]
decoded_sentence += ' ' + sampled_wor
# Exit condition: either hit max length or find stop token
if (sampled_wor == '\n' or
len(decoded_sentence) > max_decoder_seq_length * 2):
stop_condition = True
# Update the target sequence (of length 1).
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.
# Update states
states_value = [h, c]
return decoded_sentence
Everything is ready, time to talk! We only output 10 sentences for testing, it should be enough to assess the finesse of our speaking model:
for seq_index in range(10):
# Take one sequence (part of the training set)
# for trying out decoding.
input_seq = encoder_input_data[seq_index: seq_index + 1] #TODO
decoded_sentence = decode_sequence(input_seq)
print('-')
print('Input sentence:\n', input_texts[seq_index])
print('Decoded sentence:\n', decoded_sentence)
print('-')
-
Input sentence:
start_name the vaults stop_name start_eattype pub stop_eattype start_food stop_food start_pricerange more than £30 stop_pricerange start_customerrating 5 out of 5 stop_customerrating start_area stop_area start_kidsfriendly stop_kidsfriendly start_near café adriatic stop_near
Decoded sentence:
the vaults is a pub with a 5 out of 5 rating and a price range of more than £30 it is located near café adriatic
-
Input sentence:
start_name the cambridge blue stop_name start_eattype pub stop_eattype start_food english stop_food start_pricerange cheap stop_pricerange start_customerrating stop_customerrating start_area stop_area start_kidsfriendly stop_kidsfriendly start_near café brazil stop_near
Decoded sentence:
the cambridge blue is a pub near café brazil and serves english food for cheap prices
-
Input sentence:
start_name the eagle stop_name start_eattype coffee shop stop_eattype start_food japanese stop_food start_pricerange less than £20 stop_pricerange start_customerrating low stop_customerrating start_area riverside stop_area start_kidsfriendly yes stop_kidsfriendly start_near burger king stop_near
Decoded sentence:
the eagle is a low priced coffee shop that is family friendly it is located in the city center near burger king
-
Input sentence:
start_name the mill stop_name start_eattype coffee shop stop_eattype start_food french stop_food start_pricerange £20 25 stop_pricerange start_customerrating stop_customerrating start_area riverside stop_area start_kidsfriendly stop_kidsfriendly start_near the sorrento stop_near
Decoded sentence:
in the riverside area near the sorrento is a french coffee shop called the mill the price range is £20 25
-
Input sentence:
start_name loch fyne stop_name start_eattype stop_eattype start_food french stop_food start_pricerange stop_pricerange start_customerrating high stop_customerrating start_area riverside stop_area start_kidsfriendly stop_kidsfriendly start_near the rice boat stop_near
Decoded sentence:
the loch fyne is a highly rated restaurant located in the rice boat by the river
-
Input sentence:
start_name bibimbap house stop_name start_eattype stop_eattype start_food english stop_food start_pricerange moderate stop_pricerange start_customerrating stop_customerrating start_area riverside stop_area start_kidsfriendly stop_kidsfriendly start_near clare hall stop_near
Decoded sentence:
bibimbap house is a moderately priced english cuisine venue located on the riverside near clare hall
-
Input sentence:
start_name the rice boat stop_name start_eattype stop_eattype start_food french stop_food start_pricerange stop_pricerange start_customerrating average stop_customerrating start_area riverside stop_area start_kidsfriendly no stop_kidsfriendly start_near stop_near
Decoded sentence:
the rice boat is an average french restaurant located in riverside however it is not family friendly
-
Input sentence:
start_name the wrestlers stop_name start_eattype coffee shop stop_eattype start_food japanese stop_food start_pricerange less than £20 stop_pricerange start_customerrating stop_customerrating start_area riverside stop_area start_kidsfriendly no stop_kidsfriendly start_near raja indian cuisine stop_near
Decoded sentence:
the wrestlers is a japanese coffee shop near raja indian cuisine on the riverside its prices in less than £20 family friendly
-
Input sentence:
start_name aromi stop_name start_eattype coffee shop stop_eattype start_food french stop_food start_pricerange stop_pricerange start_customerrating low stop_customerrating start_area city centre stop_area start_kidsfriendly no stop_kidsfriendly start_near stop_near
Decoded sentence:
aromi coffee shop serves french food and is not family friendly the customer rating is low and it is located in the city center
-
Input sentence:
start_name the phoenix stop_name start_eattype stop_eattype start_food fast food stop_food start_pricerange moderate stop_pricerange start_customerrating 3 out of 5 stop_customerrating start_area riverside stop_area start_kidsfriendly stop_kidsfriendly start_near stop_near
Decoded sentence:
the phoenix is a fast food restaurant located in the riverside area they have a moderate price range and a customer rating of 3 out of 5
-
This is an impressive result!
Taking a look at some online examples of Sequence to Sequence models focusing on characters generation, results usually don’t make that much sense. Here, we managed to obtain something very close to the exemple given by E2E (see image at the beginning).
Interesting possibilities for improving the model could be to use Embedding Layers as proposed by Keras for token sequences, or an Attention as in this paper by Bahdanau et al. 2015.
