Aspect Based Sentiment Analysis
Sentiment analysis is a very popular technique in Natural Language Processing. We can see it applied to get the polarity of social network posts, movie reviews, or even books.
However basic sentiment analysis can be limited, as we lack precision in the evoked subject.
Let’s take the example of reviews for a computer: how do we know what is good/bad ? Is it the keyboard, the screen, the processor?
The Aspect Based Sentiment Analysis method addresses directly that limitation. Introduced during the SemEval annual competition in 2014, ABSA aim to look for the aspects term mentioned and gives the associated sentiment score.
Back to our computer example, in the following reviews:
- “I absolutely love this bright retina screen”
- “The butterfly keyboard is deceiving!”
With ABSA we would obtain a positive sentiment for the screen, and a negative sentiment for the keyboard. This is way more actionable from a business point of view.
This post will implement the ABSA task in python on a restaurant reviews dataset. Similarly to the computer example, our model should return polarity contained in the sentences about the food, ambiance, etc.
Overview
The ABSA model could be decomposed in three distinct main processes for an out-of-domain usecase:
- Learning the Aspect Categories (
SCREEN$Quality,PROCESSOR$Performance, etc.) - Finding the aspect words in sentences (
retina screen,butterfly keyboardetc.) and classify to aspect category - Computing the polarity for each aspect in each entry
However, our restaurant usecase is what we call in-domain. That is, we already have defined the aspect categories related to the reviews. We then have a model composed of two distinct models: the Aspect Categories classifier and the Sentiment Model.
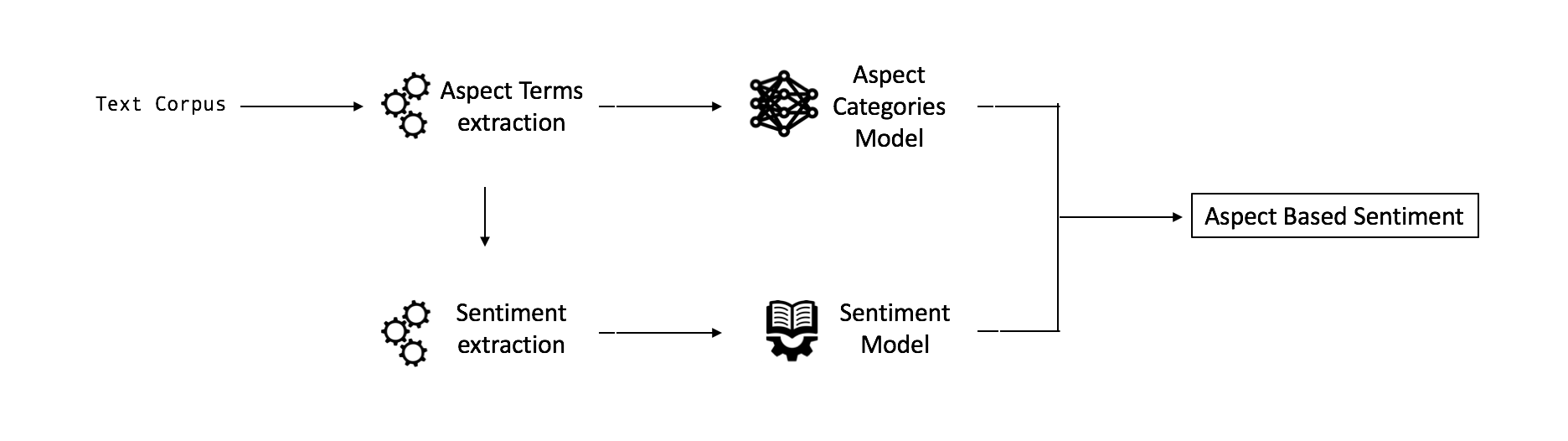
The training dataset is composed of 1503 reviews and their associated categories. There is 12 defined categories:
AMBIENCE#GENERALDRINKS#PRICESDRINKS#QUALITYDRINKS#STYLE_OPTIONSFOOD#PRICESFOOD#QUALITYFOOD#STYLE_OPTIONSLOCATIOn#GENERALRESTAURANT#GENERALRESTAURANT#MISCELLANEOUSSERVICE#GENERAL
Step 1: Get the Aspect Terms
First things first, we want to load training data:
import pandas as pd
dataset = pd.read_csv('./data/traindata.csv', sep='\t', header= None)
dataset = dataset.loc[:, [0, 1, 4]]
dataset = dataset.rename(index=str, columns={ 0: "sentiment", 1: "aspect_category", 4: "review"})
#dataset = dataset.rename(index=str, columns={ 0: "sentiment", 1: "aspect_category", 2: "review"})
dataset.head(5)
| sentiment | aspect_category | review | |
|---|---|---|---|
| 0 | positive | AMBIENCE#GENERAL | short and sweet – seating is great:it's romant... |
| 1 | positive | AMBIENCE#GENERAL | This quaint and romantic trattoria is at the t... |
| 2 | positive | FOOD#QUALITY | The have over 100 different beers to offer thi... |
| 3 | negative | SERVICE#GENERAL | THIS STAFF SHOULD BE FIRED. |
| 4 | positive | FOOD#STYLE_OPTIONS | The menu looked great, and the waiter was very... |
Now the data is ready to proceed to Aspect Terms extractions. First, we want to extract the Aspect Terms that we will feed to the Aspect Categories Classifier.
To do so we use the Noun chunk dependency parser of spaCy, a very efficient NLP library written in Cython. We don’t do that much text processing before, as certain operations modify the structure of the sentence and alter the spaCy detection.
import spacy
nlp = spacy.load('en')
dataset.review = dataset.review.str.lower()
aspect_terms = []
for review in nlp.pipe(dataset.review):
chunks = [(chunk.root.text) for chunk in review.noun_chunks if chunk.root.pos_ == 'NOUN']
aspect_terms.append(' '.join(chunks))
dataset['aspect_terms'] = aspect_terms
dataset.head(10)
| sentiment | aspect_category | review | aspect_terms | |
|---|---|---|---|---|
| 0 | positive | AMBIENCE#GENERAL | short and sweet – seating is great:it's romant... | seating |
| 1 | positive | AMBIENCE#GENERAL | this quaint and romantic trattoria is at the t... | trattoria top list |
| 2 | positive | FOOD#QUALITY | the have over 100 different beers to offer thi... | beers guest husband food dish tortelini |
| 3 | negative | SERVICE#GENERAL | this staff should be fired. | staff |
| 4 | positive | FOOD#STYLE_OPTIONS | the menu looked great, and the waiter was very... | menu waiter food |
| 5 | positive | FOOD#QUALITY | the tuna and wasabe potatoes are excellent. | potatoes |
| 6 | negative | SERVICE#GENERAL | the whole set up is truly unprofessional and i... | staff one place |
| 7 | negative | SERVICE#GENERAL | sometimes i get bad food and bad service, some... | food service service |
| 8 | positive | FOOD#STYLE_OPTIONS | this place has the best chinese style bbq ribs... | place ribs city |
| 9 | positive | AMBIENCE#GENERAL | great place to relax and enjoy your dinner | place dinner |
We can create our Aspect Categories Model! As a reminder, this model must find the Aspect Category given the Aspect Terms. To do so, we build a Convolutional Neural Network using the Keras library.
We use Sequential to initiate our model, and add layers to it:
- The first layer is a dense layer with 512 nodes. The input shape is the shape of the word vectors (see explanation below). We use the
reluactivation function (often used for faster learning). - The second layer is our output layer. Its number of nodes is the number of outputs we want. The activation function is
softmaxbecause we want a probability distribution among the Aspect Categories. We have 12 Aspect Categories, so we want 12 nodes in the layer.
Step 2: Build the Aspect Categories Model
from keras.models import load_model
from keras.models import Sequential
from keras.layers import Dense, Activation
aspect_categories_model = Sequential()
aspect_categories_model.add(Dense(512, input_shape=(6000,), activation='relu'))
aspect_categories_model.add(Dense(12, activation='softmax'))
aspect_categories_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
Using TensorFlow backend.
However we cannot directly feed words as string to the CNN, that is why we will encode our Aspect terms as vectors. This technique is called Word Embedding, and consists of representing a word by its representation as vector in a high dimensional space.
The Word Embedding technique we will use here is called Bag of Words and is very simple:
- We create a matrix of occurrence of all the words in our vocabulary. For a vocabulary of size N and M sentences, we have an $S \times M$ matrix.
- Each vector is then a one hot encoded representation according to the presence of the words
Here is a small example:

Hopefully, Keras has everything we need for this BoW word embedding.
from keras.preprocessing.text import Tokenizer
vocab_size = 6000 # We set a maximum size for the vocabulary
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(dataset.review)
aspect_tokenized = pd.DataFrame(tokenizer.texts_to_matrix(dataset.aspect_terms))
Perfect, we also want to encode the aspect_category to dummy (binary) variables using Sklearn and Keras:
from sklearn.preprocessing import LabelEncoder
from keras.utils import to_categorical
label_encoder = LabelEncoder()
integer_category = label_encoder.fit_transform(dataset.aspect_category)
dummy_category = to_categorical(integer_category)
Learning time! Just one line of code to fit the model with input the encoded aspect terms and output the encoded aspect categories.
The number of epochs is kept relatively low to avoid overfitting.
aspect_categories_model.fit(aspect_tokenized, dummy_category, epochs=5, verbose=1)
Epoch 1/5
1503/1503 [==============================] - 3s 2ms/step - loss: 2.1023 - acc: 0.3919
Epoch 2/5
1503/1503 [==============================] - 2s 1ms/step - loss: 1.4605 - acc: 0.5349
Epoch 3/5
1503/1503 [==============================] - 2s 1ms/step - loss: 1.1604 - acc: 0.6394
Epoch 4/5
1503/1503 [==============================] - 2s 1ms/step - loss: 0.9615 - acc: 0.6806
Epoch 5/5
1503/1503 [==============================] - 2s 1ms/step - loss: 0.8294 - acc: 0.7152
<keras.callbacks.History at 0x1106940f0>
Let’s try our Aspect Categories model on a new review. We have to do the same processing operations on that review and then predict using model.predict. And not forget to transform the output using inverse_encode.
new_review = "This italian place is nice and cosy"
chunks = [(chunk.root.text) for chunk in nlp(new_review).noun_chunks if chunk.root.pos_ == 'NOUN']
new_review_aspect_terms = ' '.join(chunks)
new_review_aspect_tokenized = tokenizer.texts_to_matrix([new_review_aspect_terms])
new_review_category = label_encoder.inverse_transform(aspect_categories_model.predict_classes(new_review_aspect_tokenized))
print(new_review_category)
['RESTAURANT#GENERAL']
This review is indeed about the restaurant in general! We can go on to the most sentimental parts of this article :-)
Step 3: Get the Sentiment Terms
Now, we want to keep from our reviews only the words which can indicate if the expressed opinion is positive or negative.
We use spaCy once again, but this time we are going to use Part Of Speech Tagging to filter and keep only adjectives and verbs.
sentiment_terms = []
for review in nlp.pipe(dataset['review']):
if review.is_parsed:
sentiment_terms.append(' '.join([token.lemma_ for token in review if (not token.is_stop and not token.is_punct and (token.pos_ == "ADJ" or token.pos_ == "VERB"))]))
else:
sentiment_terms.append('')
dataset['sentiment_terms'] = sentiment_terms
dataset.head(10)
| sentiment | aspect_category | review | aspect_terms | sentiment_terms | |
|---|---|---|---|---|---|
| 0 | positive | AMBIENCE#GENERAL | short and sweet – seating is great:it's romant... | seating | short sweet great be romantic cozy private |
| 1 | positive | AMBIENCE#GENERAL | this quaint and romantic trattoria is at the t... | trattoria top list | quaint romantic manhattan |
| 2 | positive | FOOD#QUALITY | the have over 100 different beers to offer thi... | beers guest husband food dish tortelini | different offer thi happy delicious recommend |
| 3 | negative | SERVICE#GENERAL | this staff should be fired. | staff | fire |
| 4 | positive | FOOD#STYLE_OPTIONS | the menu looked great, and the waiter was very... | menu waiter food | look great nice come average |
| 5 | positive | FOOD#QUALITY | the tuna and wasabe potatoes are excellent. | potatoes | excellent |
| 6 | negative | SERVICE#GENERAL | the whole set up is truly unprofessional and i... | staff one place | unprofessional wish good current great |
| 7 | negative | SERVICE#GENERAL | sometimes i get bad food and bad service, some... | food service service | bad bad good good bad |
| 8 | positive | FOOD#STYLE_OPTIONS | this place has the best chinese style bbq ribs... | place ribs city | good chinese |
| 9 | positive | AMBIENCE#GENERAL | great place to relax and enjoy your dinner | place dinner | great relax enjoy |
Step 4: Build the Sentiment Model
For the sentiment model, we use a very similar architecture than in step 2:
- A dense layer that take as input word vectors of dimension 6000, with a
reluactivation function and 512 nodes. - An output layer with a
softmaxactivation function to output probability distribution. This time with only 3 nodes because we want to predict positive, negative or neutral.
sentiment_model = Sequential()
sentiment_model.add(Dense(512, input_shape=(6000,), activation='relu'))
sentiment_model.add(Dense(3, activation='softmax'))
sentiment_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
The input is going to be the feature sentiment_terms, but we need to use the same encoding process as for the aspect terms. This time we don’t have to create and fit a Tokenizer, because it already has been done on the entire review dataset in step 2.
sentiment_tokenized = pd.DataFrame(tokenizer.texts_to_matrix(dataset.sentiment_terms))
The output is the feature sentiment, which requires an encoding to dummy variable. We need to create a new labelEncoder because we have only 3 categories, which is different from the 12 aspect categories.
label_encoder_2 = LabelEncoder()
integer_sentiment = label_encoder_2.fit_transform(dataset.sentiment)
dummy_sentiment = to_categorical(integer_sentiment)
Time to fit our second model ! The code is very similar here, and the CNN should fit the data even better considering than the classification is easier.
sentiment_model.fit(sentiment_tokenized, dummy_sentiment, epochs=5, verbose=1)
Epoch 1/5
1503/1503 [==============================] - 3s 2ms/step - loss: 0.7994 - acc: 0.6886
Epoch 2/5
1503/1503 [==============================] - 2s 1ms/step - loss: 0.5105 - acc: 0.7878
Epoch 3/5
1503/1503 [==============================] - 2s 1ms/step - loss: 0.3913 - acc: 0.8530
Epoch 4/5
1503/1503 [==============================] - 2s 1ms/step - loss: 0.3209 - acc: 0.8669
Epoch 5/5
1503/1503 [==============================] - 2s 1ms/step - loss: 0.2860 - acc: 0.8776
<keras.callbacks.History at 0x13772d160>
new_review = "This italian place is nice and cosy"
chunks = [(chunk.root.text) for chunk in nlp(new_review).noun_chunks if chunk.root.pos_ == 'NOUN']
new_review_aspect_terms = ' '.join(chunks)
new_review_aspect_tokenized = tokenizer.texts_to_matrix([new_review_aspect_terms])
new_review_category = label_encoder_2.inverse_transform(sentiment_model.predict_classes(new_review_aspect_tokenized))
print(new_review_category)
['positive']
Putting everything together
We now finally have both the Aspect Categories and the Sentiment models! Let’s define new reviews and apply our entire ABSA implementation:
test_reviews = [
"Good, fast service.",
"The hostess was very pleasant.",
"The bread was stale, the salad was overpriced and empty.",
"The food we ordered was excellent, although I wouldn't say the margaritas were anything to write home about.",
"This place has totally weird decor, stairs going up with mirrored walls - I am surprised how no one yet broke their head or fall off the stairs"
]
# Aspect preprocessing
test_reviews = [review.lower() for review in test_reviews]
test_aspect_terms = []
for review in nlp.pipe(test_reviews):
chunks = [(chunk.root.text) for chunk in review.noun_chunks if chunk.root.pos_ == 'NOUN']
test_aspect_terms.append(' '.join(chunks))
test_aspect_terms = pd.DataFrame(tokenizer.texts_to_matrix(test_aspect_terms))
# Sentiment preprocessing
test_sentiment_terms = []
for review in nlp.pipe(test_reviews):
if review.is_parsed:
test_sentiment_terms.append(' '.join([token.lemma_ for token in review if (not token.is_stop and not token.is_punct and (token.pos_ == "ADJ" or token.pos_ == "VERB"))]))
else:
test_sentiment_terms.append('')
test_sentiment_terms = pd.DataFrame(tokenizer.texts_to_matrix(test_sentiment_terms))
# Models output
test_aspect_categories = label_encoder.inverse_transform(aspect_categories_model.predict_classes(test_aspect_terms))
test_sentiment = label_encoder_2.inverse_transform(sentiment_model.predict_classes(test_sentiment_terms))
for i in range(5):
print("Review " + str(i+1) + " is expressing a " + test_sentiment[i] + " opinion about " + test_aspect_categories[i])
Review 1 is expressing a positive opinion about SERVICE#GENERAL
Review 2 is expressing a positive opinion about SERVICE#GENERAL
Review 3 is expressing a negative opinion about FOOD#QUALITY
Review 4 is expressing a positive opinion about FOOD#QUALITY
Review 5 is expressing a negative opinion about AMBIENCE#GENERAL
We indeed identify the sentiment expressed in each review and the main topic addressed with precision, for each of the five reviews!
